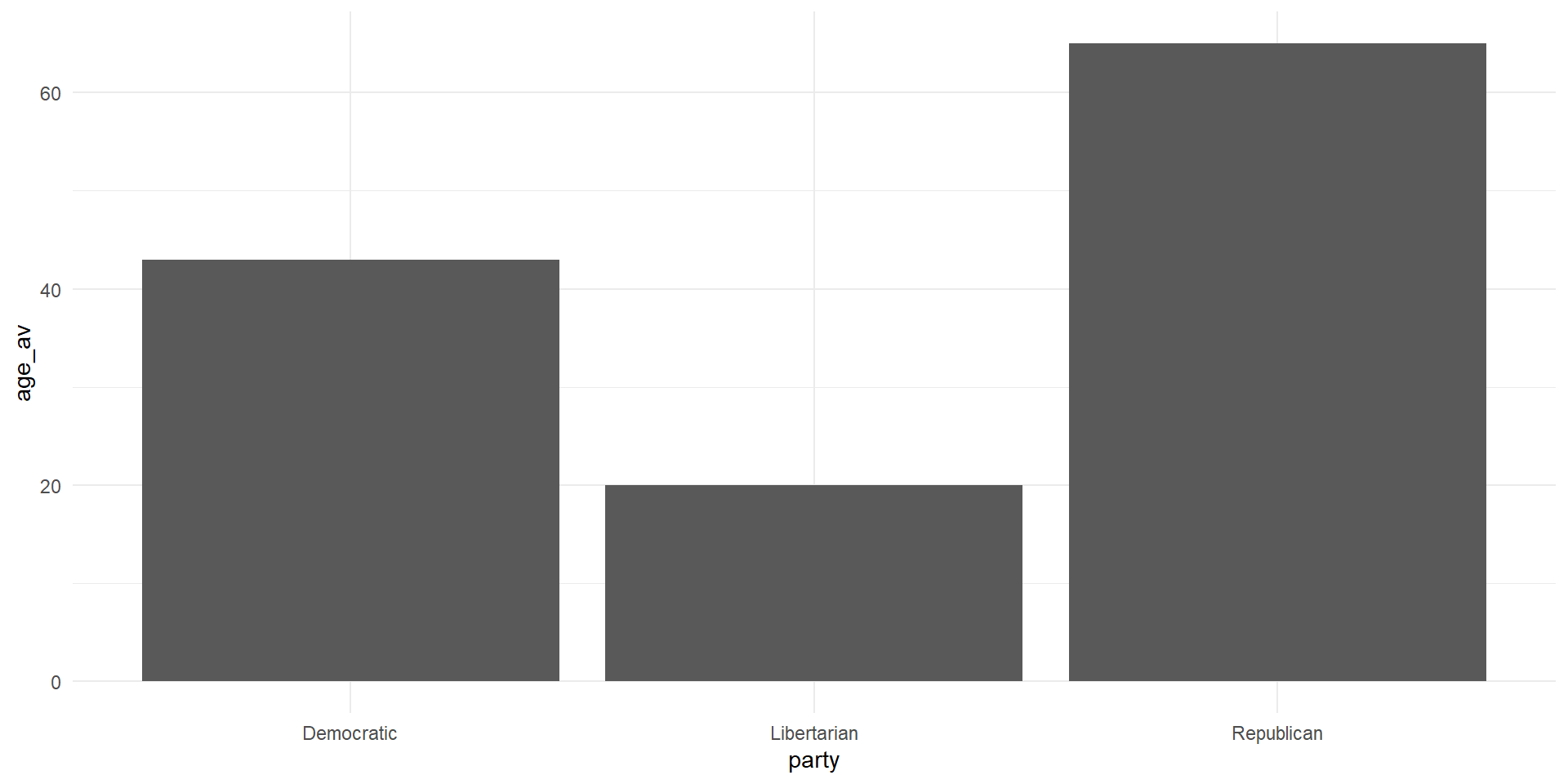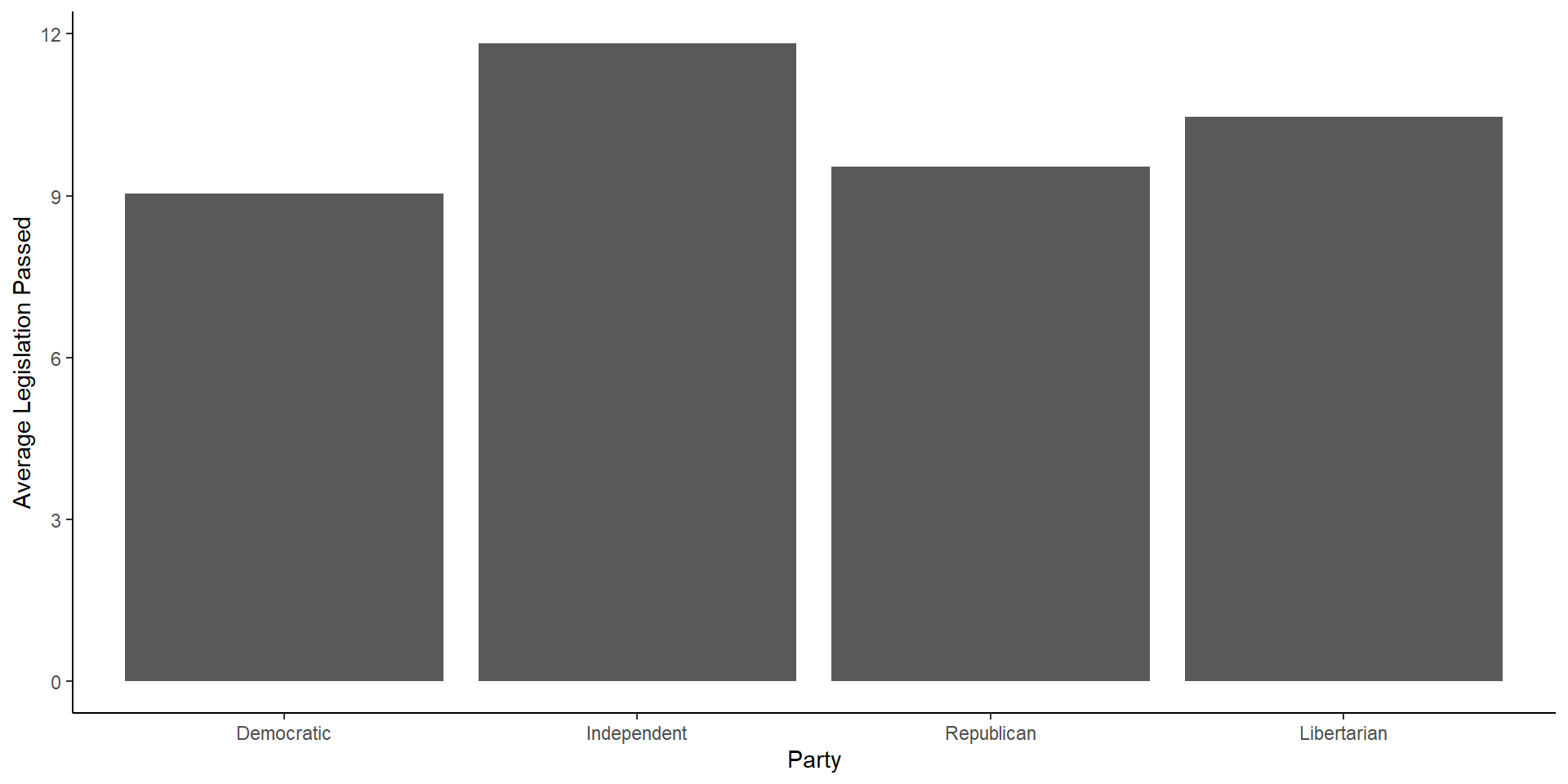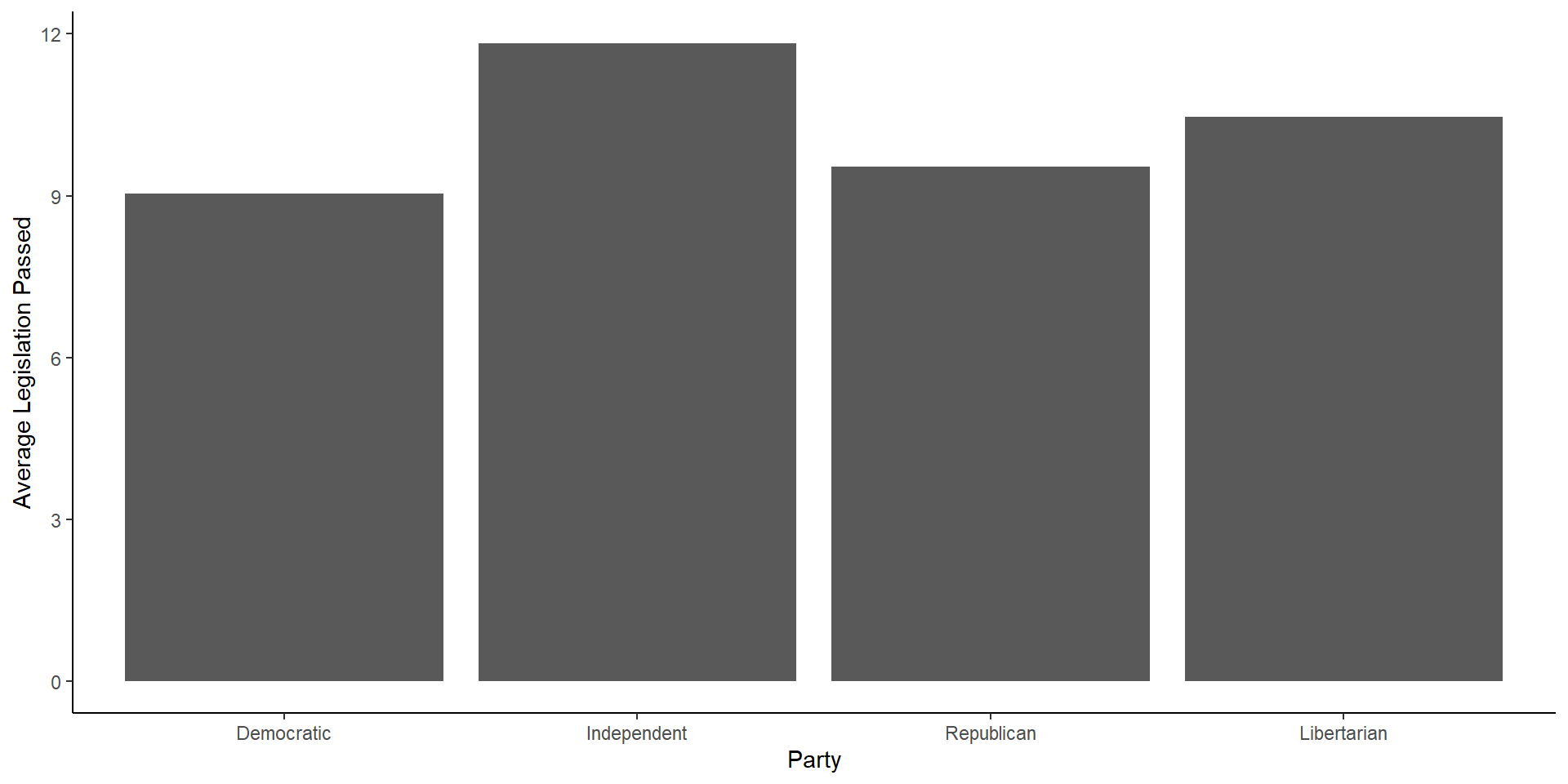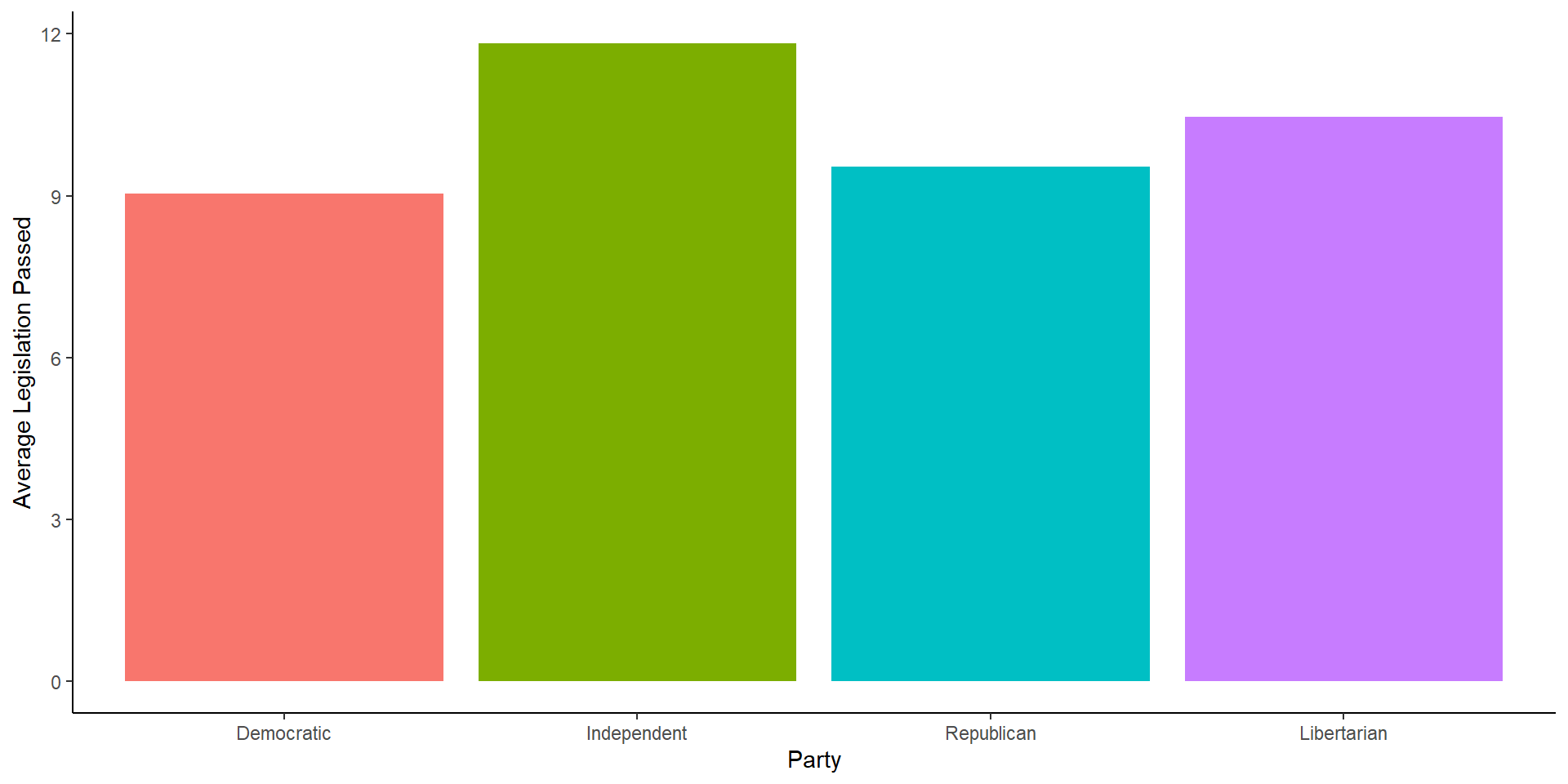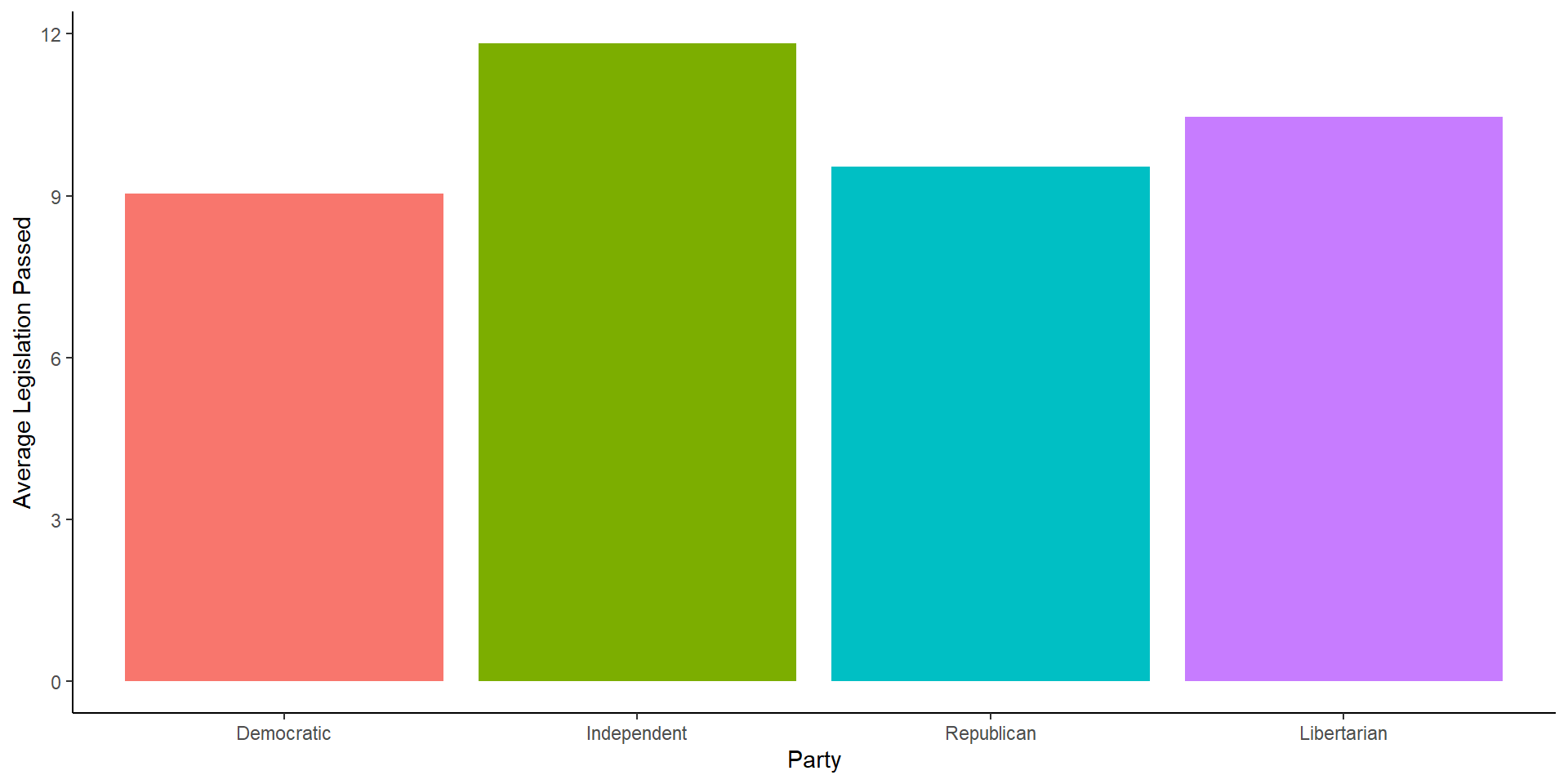More practice using mutate(), filter(), group_by(), and summarize()
More on factor()
Making something pretty
Homework comments
Everyone did great!
Two noteworthy things:
Y’all found functions I didn’t teach you (drop_na(), and na.omit() were two I noticed)
Only one person looked further into the values of their variables of interest
Becoming Familiar with Data
library(tidyverse)## reading in the ANES data directly from the linkanes <-read_csv('https://www.dropbox.com/scl/fi/i6gp3y8ctmwxs1lp705ax/anes.csv?rlkey=44twem0nyu6tdq65sv2wlw93c&dl=1')## pulling out some variablesanes %>%rename('pid'= V201018,'gender'= V201600) %>%select(pid,gender) -> anes_datatable(anes_data$pid)
Note that we reshaped the variable to remove “other” by only allowing for values 1-3 in the factor
Practicing concepts from Day 1
Group Work
On the course website, under Day 1 3, download the Olympics data and do the following:
Read the data into R
Use select() so the data only has the country, winter, and summer variables.
Rename the variables to something that makes sense
Make a new variable that is the total number of medals:
hint: you will need to use the rowwise() to sum in each row, I will put that on the board when everyone is ready
Use filter() to show the results for only one country
Use filter() to remove one country
Rowwise Code
#remember to put the name of your own data here data %>%rowwise() %>%mutate()
library(tidyverse)# 1. Reading in the dataread.csv('olympics.csv') -> olympics# 2. keeping only the variables that we wantolympics %>%select(X0, X1, X6) -> olympics# 3. Renaming the varibales to something that makes senseolympics %>%rename('country'= X0,'summer'= X1,'winter'= X6) -> olympics# 4. Making new variable for the totalolympics %>%slice(-1) %>%rowwise() %>%mutate(total =sum(parse_number(summer), parse_number(winter))) -> olympics# 5. Filtering for only Germanyolympics %>%filter(country =='Germany')# 6. Filtering to remove Chileolympics %>%filter(country !='Chile')
ggplot (finally)
Now that we’ve all mastered manipulating data, let’s learn how to paint a picture
R has a default plot function plot() that you should play around with at some point
Within the tidyverse package, there is a function & package called ggplot
ggplot is an incredibly powerful method for creating graphics
The resources page on the website points out a few books that help learn more on ggplot, for now, lets get into the basics
The Parts of ggplot
ggplot has several important components
ggplot() is how any graph is started, it takes the argument of data, and aes() or aesthetic
Within aes(), you set things such as the x and y variables
Rather than using %>% to pipe between lines, we use a +
The packages were made by the same guy, I don’t know why he did this but apparently to fix it would be a huge pain in the butt
“geoms” are how you actually decide what type of graph you’re making
Some examples are geom_bar(), geom_density(), or geom_point()
Lastly, the theme, which determines how the graph is presented
You can use preset option, such as theme_minimal() or theme_classic() or use the theme() function to change things individually, or both together!
# A tibble: 4 × 7
full_name party state age years_served votes_received legislation_passed
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 John Smith Demo… Cali… 45 6 24000 12
2 Jimmy Dean Repu… Texas 65 NA NA 10
3 Emily Davis Demo… <NA> 41 4 20000 6
4 Michael Brown Libe… Flor… 20 12 32000 15
Actually Using ggplot Code
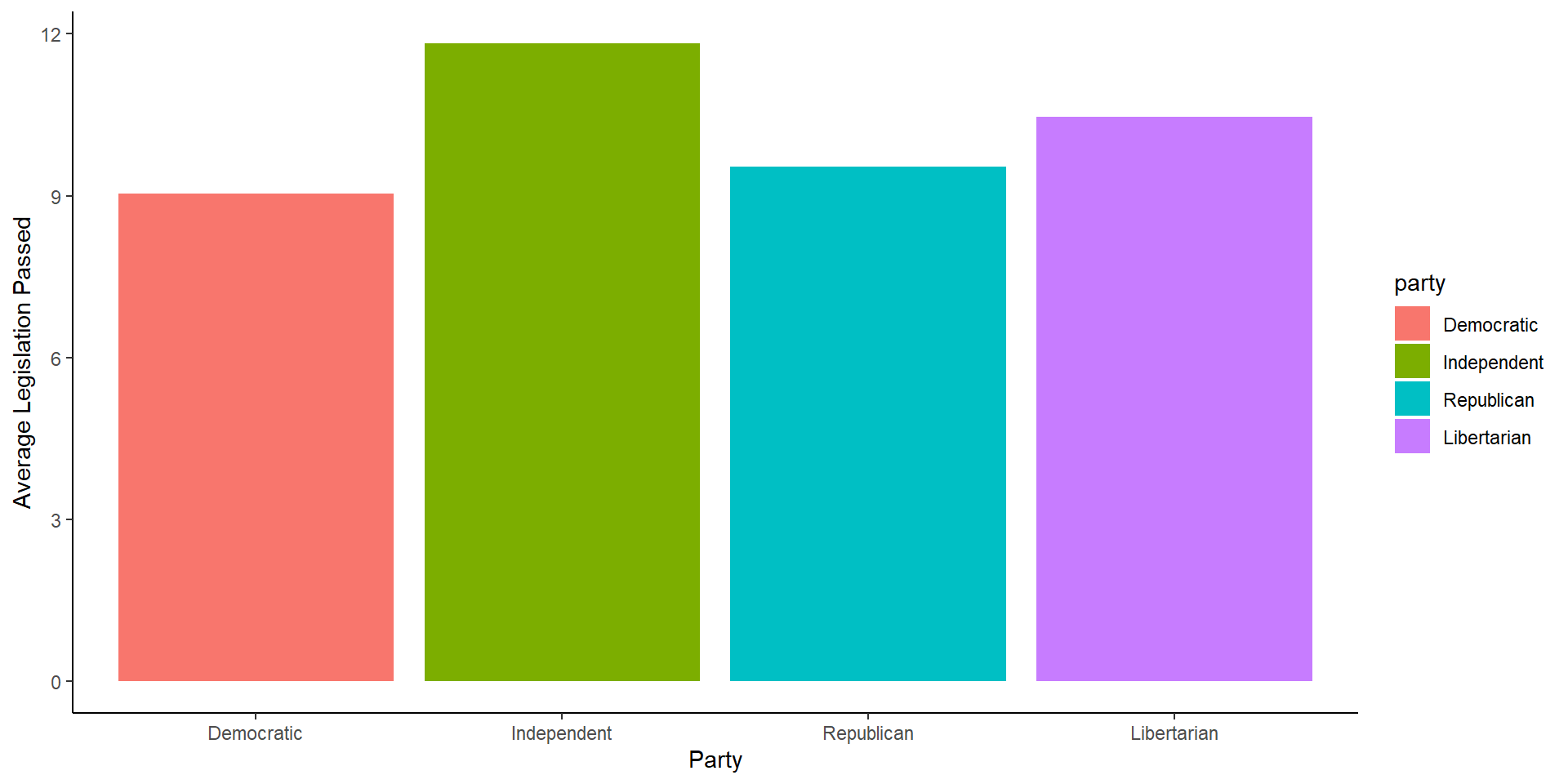
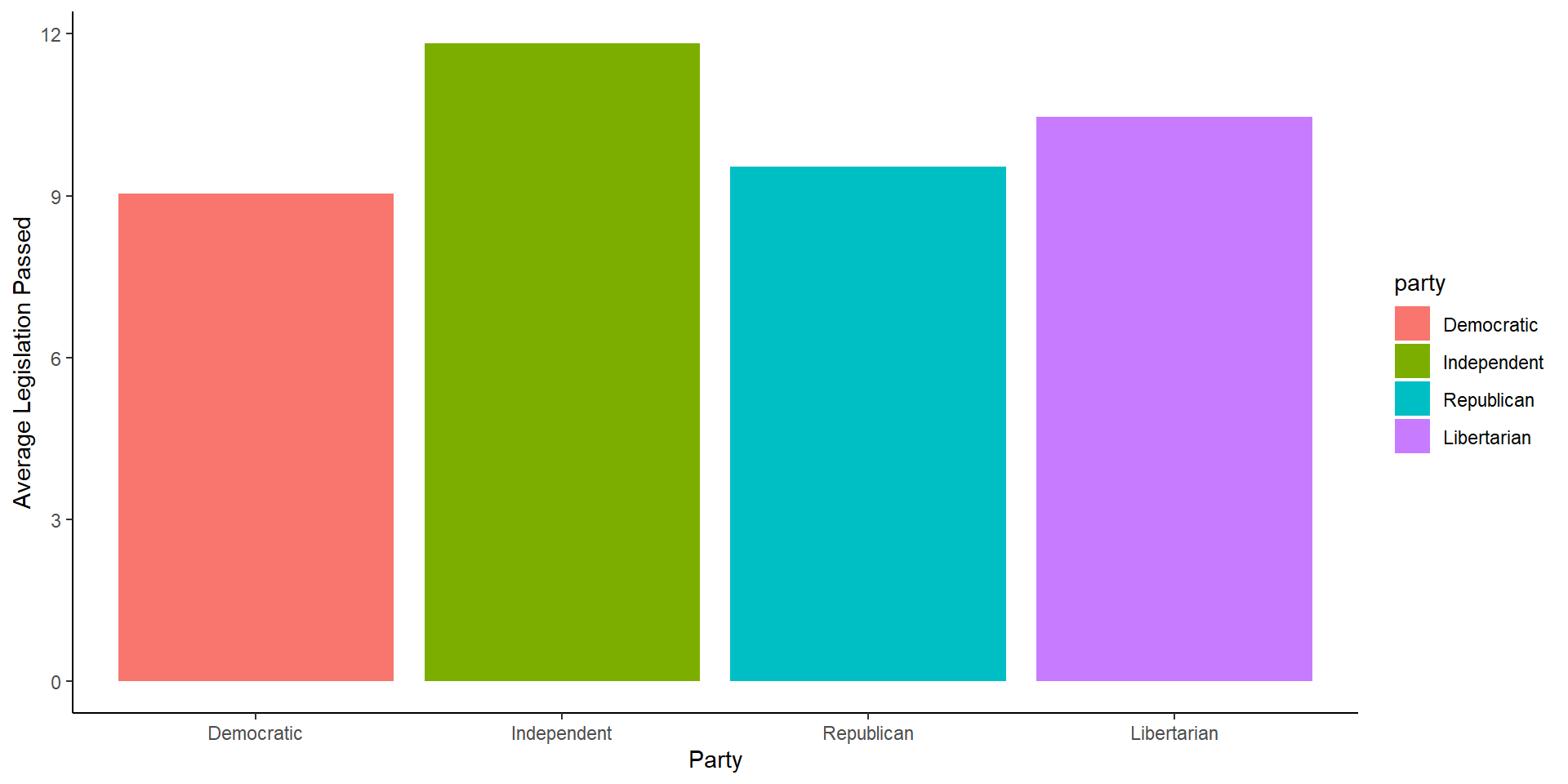
There are many ways to graph an average using ggplot, for now, we can use the code from above on finding a group average and go from there